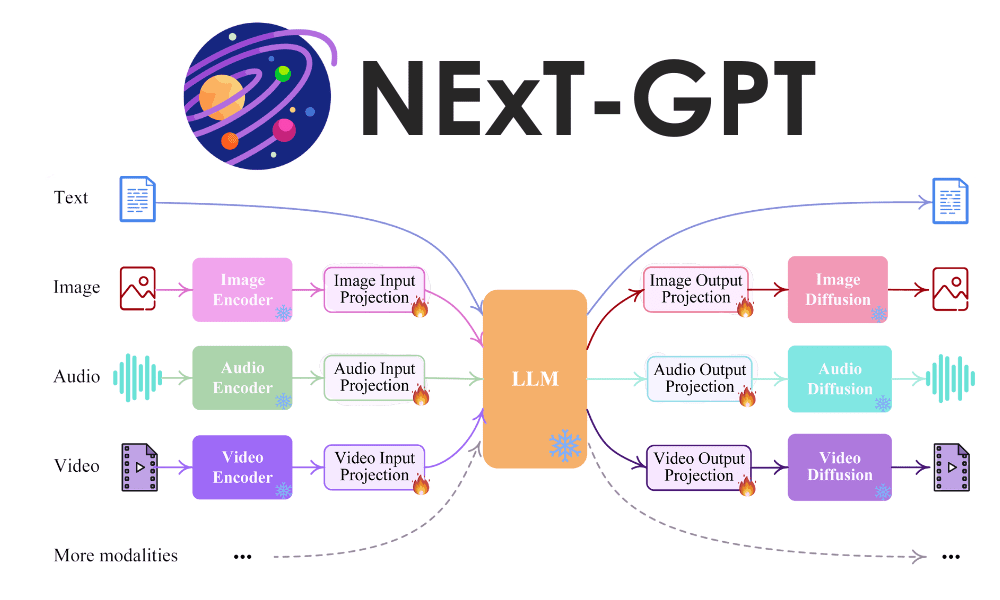
NExT-GPT, a multimodal model developed by the National University of Singapore, can transform any input into any output, handling text, images, videos, and audio. The model uses encoders for various modalities, an open-source language-like model (LLM) for semantic understanding, and modality-switching instruction tuning to align with user intentions. The model’s best performance is in transforming text and audio inputs into images.
Read more at KDnuggets…