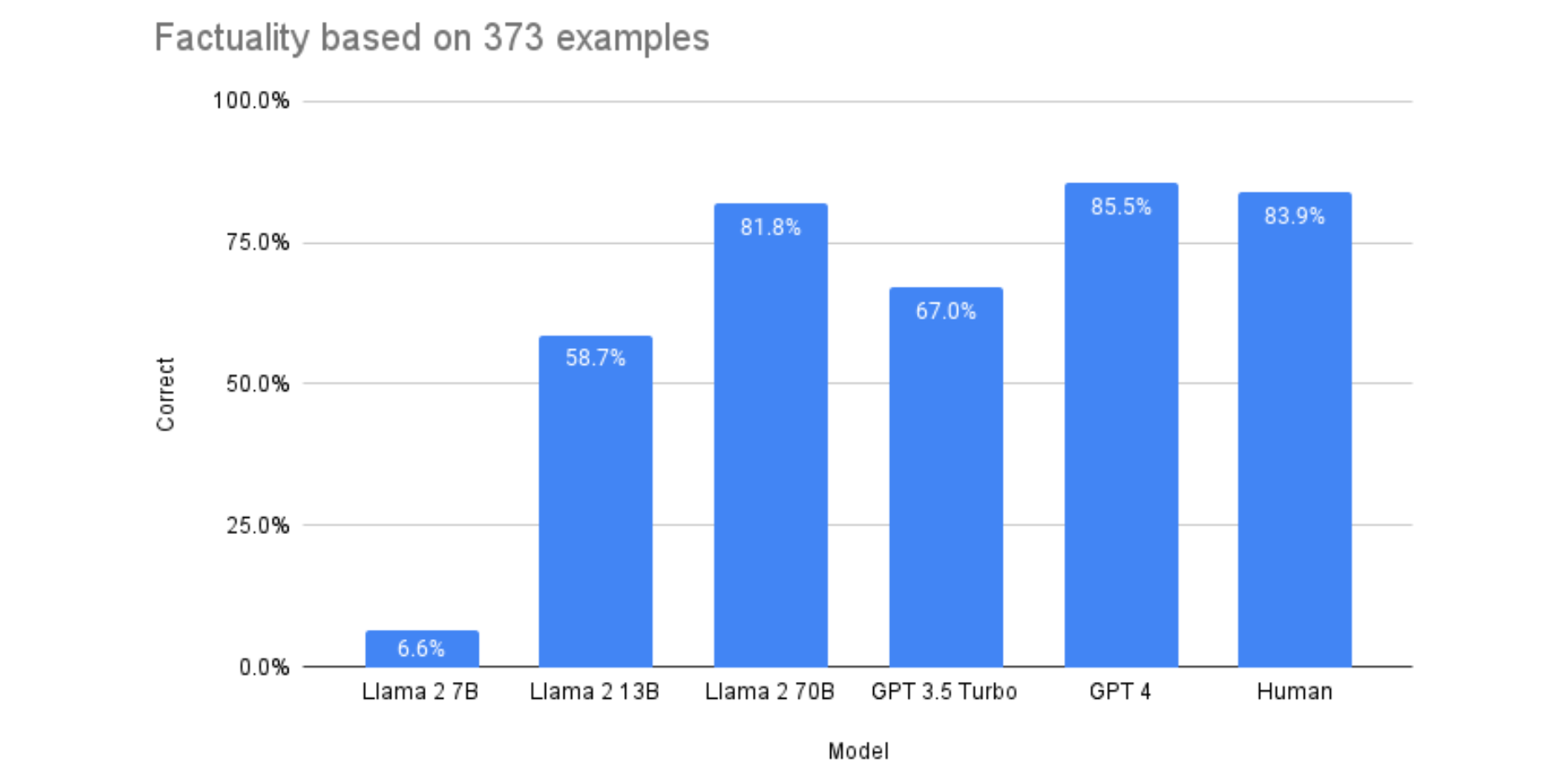
Open-source language model Llama-2-70b is nearly as accurate as GPT-4 in producing factual summaries, according to a recent experiment. Despite Llama-2-70b’s tokenization being 19% longer than GPT-4’s, it is 30 times cheaper, making it a cost-effective alternative for accurate summarization tasks. Smaller models like Llama-2-7b and Llama-2-13b, however, struggled with task instructions and exhibited ordering bias issues.
Read more at Anyscale…